
Note: This is a modified version of the project report that our HPCExperiment.com team wrote for the project organizers at the conclusion of the online HPC experiment. The work involved the use of CST Microwave Studio on the Amazon Web Services cloud.
A central landing page linking to all posts about this subject will always be at https://bioteam.net/blog/tech/cloud/cst-studio-on-the-cloud/
Experiment Summary
The project task was the simulation of a multiresonant antenna system using the commercial CAE software CST Design Studio. Different solver technologies have been evaluated, including a time domain, frequency domain and eigenmode solver.
The CST software suite offers multiple methods to accelerate simulation runs. On the node level (single machine) multithreading and GPU computing (for a subset of all available solvers) can be used to accelerate simulations still small enough to be handled by a single machine.
If a simulation project needs multiple independent simulation runs (e.g. in a parameter sweep or for the calculation of different frequency points) which are independent of each other these simulations can be sent to different machines to execute in parallel. This is done by the CST Distributed Computing System which takes care of all data transfer operations necessary to perform this parallel execution.
In addition very large models can be handled by MPI parallelization using a domain decomposition approach.
During the 3-month experiment we concentrated on the Distributed Computing system in which the simulations running in parallel on the different machines were also accelerated by multithreading and GPUs.
The Team: The end-user was a PhD physicist & engineer working for a medical device manufacturer as R&D Group Leader and innovation manager responsible for new sensor applications, new markets and fundamental research. The commercial software provider was represented by Dr.-Ing Felix Wolfheimer, Senior Application Engineer with CST AG. The HPC mentor was Chris Dagdigian a Principal Consultant employed by the BioTeam. Our resource provider was Amazon Web Services.
Use Case That Initiated This Experiment
- Application Domain: The end user uses CAE for virtual prototyping and design optimization on sensors and antenna systems used in medical imaging devices. Advances in hardware and software have enabled the end-user to simulate the complete RF-portion of the involved antenna system. Simulation of the full system is still computationally intensive although there are parallelization and scale-out techniques that can be applied de-pending on the particular “solver” method being used in the simulation.
- Current Challenges: The end-user has a highly-tuned and over-clocked local HPC cluster. Benchmarks suggest that the local HPC cluster nodes are roughly 2x faster than the largest of the cloud-based Amazon Web Services resources used for this experiment. However, the local HPC cluster averages 70% utilization at all times and the larger research-oriented simulations the end-user was interested in could not be run during normal business hours without impacting production engineering efforts.
- Why Cloud? Remote cloud-based HPC resources offered the end-user the ability to “burst” out of the local HPC system and onto the cloud. This was facilitated both by the architecture of the commercial CAE software as well as the parallelizable nature of many of the “solver” methods.
Step-by-Step Experiment Process (Mistakes included!)
Note: See below for more details, specifics, diagrams and data on some of these steps.
- Project team worked together to define and describe the ideal end-user experiment
- Initial contacts made with software provider (CST) and resource provider (AWS)
- Solicit feedback from CST engineers on recommended “cloud bursting” methods; secure licenses
- [CST Cloud Design Pattern #1] Team proposes a Hybrid Windows/Linux Cloud Architecture #1 (EU based)
- Team abandons Cloud Architecture #1; The end-user prefers to keep simulation input data within EU-protected regions. However, AWS has resources the team requires that did not yet exist in EU AWS regions. Because of this resource constraint, the end-user modified the experiment to use synthetic simulation data which enables the use of US-based systems.
- [CST Cloud Design Pattern #2] The team assembles Hybrid Windows/Linux Cloud Architecture #2 (US based) & implements it at small scale for testing and evaluation
- The team abandons Cloud Architecture #2. Heavily secured virtual private cloud (VPC) resource segregation front-ended by an internet-accessible VPN gateway looked good on paper however AWS did not have GPU nodes (or the large cc2.* instance types) within VPC at the time and the commercial CAE software had functionality issues when forced to deal with NAT translation via a VPN gateway server.
- [CST Cloud Design Pattern #3] Propose Hybrid Windows/Linux Cloud Architecture #3 & implement at small scale for testing
- The third design pattern works well; user begins to scale up simulation size
- Amazon announces support for GPU nodes in EU region and GPU nodes within VPC environments; end-user is also becoming more familiar with AWS and begins experimenting with Amazon Spot Market to reduce hourly operating costs by very significant amount
- [CST Cloud Design Pattern #4] Hybrid Windows/Linux Cloud Architecture #3 is slightly modified. The License Server remains in the USA however all solver and simulation systems are relocated to Amazon EU region in Ireland for performance reasons. End-user switches all simulation work to inexpensively sourced nodes from the Amazon Spot Market.
- The “Design Pattern #4” in which solver/simulation systems are running on AWS Spot Market Instances in Ireland while a small license server remains in the USA reflect the final “design”.
Challenges Encountered
Geographic constraints on data: The end-user had real simulation & design data that could not leave the EU. In order to enable use of US-based resources, the end user had to switch to artificial data and simulated designs.
Unequal availability of AWS resources between Regions: At the start of the experiment, some of the preferred EC2 instance types (including GPU nodes) were not yet available in the EU region (Ireland). This disparity was fixed by Amazon during the course of the experiment. The initial workaround was to operate in the AWS US-EAST region. At the end of the experiment we had migrated the majority of our simulation systems back to Ireland.
Performance of Remote Desktop Protocol. The CAE software used in this experiment makes use of Microsoft Windows for experiment design, submission and visualization. Using RDP to access remote Windows systems was very difficult for the end-user, especially when the Windows systems were operating in the USA. Performance was better when the Windows systems were relocated to Ireland but still not optimal.
CST Software and Network Address Translation (NAT). The simulation software assumes direct connections between participating client, solver and front-end systems. The CAE simulation software is non-functional when critical components are behind NAT gateways. The cloud architecture was redesigned so that essential systems were no longer isolated within secured VPC network zones. A hardware-based VNC connection between Amazon and the end-user allowing remote IP subnets to extend into the private Amazon VPC would have resolved this issue as NAT translation would not have been necessary.
Bandwidth between Linux solvers & Windows Front-End. The technical requirements of the CAE software allow for the Windows components to be run on relatively small AWS instance types. However, when large simulations are underway a tremendous volume of data flows between the Windows system and the Linux solver nodes. This was a significant performance bottleneck throughout the experiment. The heavy data flows between the Windows and Linux systems are native to the design of the CAE software stack and could not be changed. The project team ended up running Windows on much larger AWS instance types to gain access to 10GbE network connectivity options.
Node-locked software licenses. The CAE software license breaks if the license server node changes it’s network hardware (MAC address). Simply rebooting or restarting a standard AWS node results in a new server with a different MAC address and a non-functional license environment. The only way to keep a permanent and persistent MAC address in a the dynamic AWS cloud environment is to create and assign an Elastic Network Interface (ENI). However, ENIs are only supported within Amazon Virtual Private Cloud (VPC) zones and not the “regular” EC2 compute cloud. The project team ended up leveraging multiple AWS services (VPC, ENI, ElasticIP) in order to operate a persistent, reliable and reboot-able li-cense serving framework.
Spanning Amazon Regions. It is easy in theory to talk about cloud architectures that span multiple geographic regions. It is much harder to implement this “for real”. Our HPC resources switched between US and EU-based Amazon facilities several times during the lifespan of the project. Our project required the creation, management and maintenance of multiple EU and US specific SSH keys, server images (AMIs) and EBS disk volumes. Managing and maintaining capability to operate in the EU or US (or both) required significant effort and investment.
Cloud Architectures We Tried
Design #1
Click on the image for a full sized (PNG) version of the design.

This was our first design and on paper it looked fantastic. In reality it was also very nice but there were a few problems (some temporary, some unresolvable) that forced us to move to a different design.
The Good:
- 100% of our infrastructure isolated inside an AWS VPC. External access via a VPN server that we controlled
- Isolated VPC subnets for servers expected to touch the internet vs. “everything else” with isolation enforced by routing rules and ingress/egress rules within VPC Security Groups
- Complete control over the MAC addresses of all nodes via VPC ENIs (Elastic Network Interface). We really only needed this for the flexLM license server but it was a nice feature to have throughout
- For some things, working inside a VPC is actually easier than running purely within AWS EC2. ENIs don’t exist in EC2. In EC2 you can’t change the Security Group of a running instance. Inside VPC we can make ingress/egress rule changes in VPC SGs and watch the changes get applied instantly.
The Bad (temporary)
- At the time we launched this architecture, we found out that GPU nodes and the largest of the compute cluster instance types were not yet available inside VPC zones. By the time our experiment was completed this was no longer a constraint (a good example of the fast rate of change in the IaaS cloud/feature space…). At the time, however, it forced us to change our design thoughts.
The bad (unresolvable at this time)
- At the time of this work, CST Studio software did not cleanly handle cases where IP addresses go through NAT translation. Our original intent was to have both “solver” nodes and FrontEnd nodes running at the location of our end-user. This would represent a real “hybrid cloud” design pattern with local resources augmenting cloud-based resources. This actually does work and is something that CST supports but only if there is direct IP-to-IP connectivity without NAT or IP-related tricks.
Design #2
Click on the image for a full sized (PNG) version of the design.

This was our second design. We dropped the VPN portion since our remote nodes could not handle NAT and we also dropped the VPC so that we could use the largest CC.* instance types as well as the GPU-enabled instances as CST solvers.
The Good:
- It worked and the architecture is easy to understand. Running in a single AZ within a single EC2 security group
The Bad:
- Running at scale quickly became expensive. At this point we were not making use of the extraordinary AWS Spot Market
Design #3 (Final)
Click on the image for a full sized (PNG) version of the design.
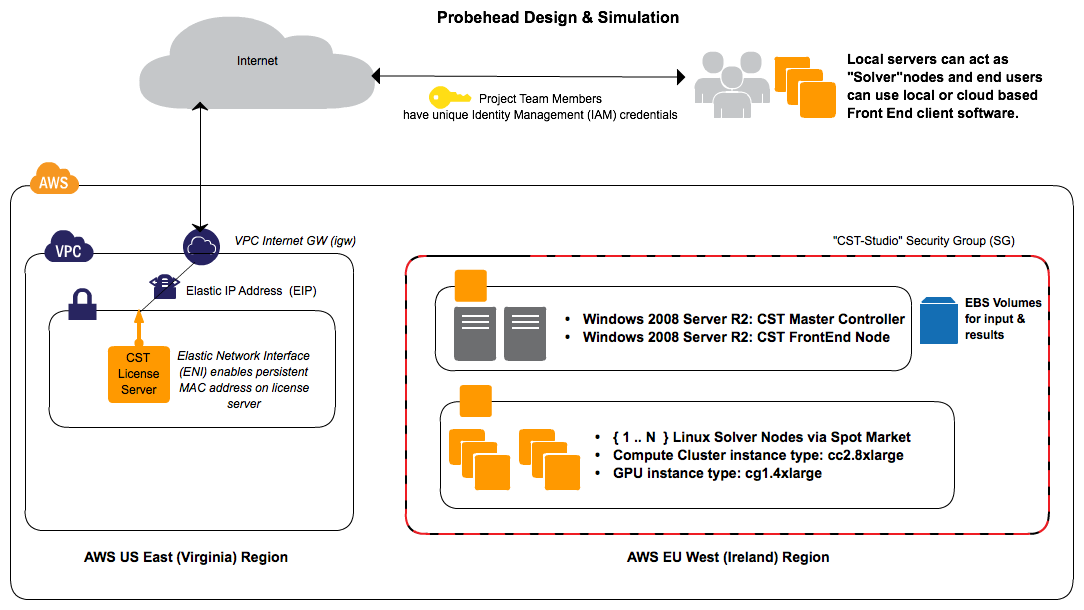
This was the final design. We added back a VPC simply so we could have a license server with a known and persistant MAC address. We moved all computation to Ireland and all of the worker/solver nodes were run via the AWS Spot Market for a significant cost savings.
The Good:
- No more worries about the license server; we rebuilt a VPC, constructed an ENI and ran the license server within it
- Moved the computation to Ireland (closer to our end user) and saw significant increase in performance/usefulness of remote FrontEnd software running at the office location of our end-user
- This design (no VPC / NAT for solver nodes) allowed us to reintroduce FrontEnd and Solver node resources that lived at the office location of our end user. The end result is a Hybrid Cloud that actually worked rather than delusional market speak discussing a cherry picked and carefully tuned “customer example” vomited into a powerpoint deck
- Very significant cost savings realized by using the AWS Spot Market for computation
The bad:
- Not really anything bad to say. This design pattern worked very well for us
Outcome & Benefits
Note: The end user, software provider & HPC mentor were asked for comments and impressions. This is what they said.
End-User
- Confirmation that a full system simulation is indeed possible even though there are heavy constraints, mostly due to the CAE software. Model setup, meshing and postprocessing are not optimal and re-quire huge efforts in terms of manpower and CPU-time.
- Confirmation that a full system simulation can reproduce certain problems occurring in real devices and can help to solve those issues
- Realize the reasonable financial investment for additional computation resources needed for cloud bursting approaches.
CAE Software Provider
- Confirmation that the software is able to be setup and run within a cloud environment and also, in principle, using a cloud bursting approach. Some very valuable knowledge on how to setup an “elastic cluster” in the cloud using best practices regarding security, stability and price in the Amazon EC 2 environment.
- Experience the limitations and pitfalls specific to the Amazon EC2 configuration (e.g. availability of re-sources in different areas, VPC needed to preserve MAC addresses for licensing setup, network speed, etc.).
- Experiencing the restrictions of the IT department of a company when it comes to the integration of cloud resources (specific to the cloud bursting approach).
HPC Mentor
- Chance to use Windows-based HPC systems on the cloud in a significant way was very helpful
- New appreciation for the difficulties in spanning US/EU regions within Amazon Web Services


