Schrödinger Best Practices vs AWS PCS Limits

Modern HPC integration practices for Schrödinger workloads tend to want 10–12 Slurm partitions and matching host entries, because Maestro doesn’t let chemists pass Slurm arguments directly. That design preference collided with AWS Parallel Computing Service on a recent deployment: PCS has a hard, non-adjustable cap of 10 partitions and 10 compute node groups per cluster. […]
AWS PCS resolves Licenses length issue

Good news: The 1024-character limit in the AWS PCS custom slurm configuration parameter that enables license-aware job scheduling was recognized by AWS as a “bug” and recently resolved. The new character limit is 2048. TL;DR AWS Parallel Computing Service (PCS) previously capped every slurmCustomSettings.parameterValue at 1,024 characters. The limit applied uniformly through Terraform, the AWS […]
Schrödinger 2026-1 and broken jsc certs

Note: This post is pure google bait designed to help others who run into the same problem. We hope it helps! 16-April-2026: Correction – Schrödinger has documented this issue and a workaround at https://my.schrodinger.com/support/article/629509 You upgraded jobserverd, your functionality tests ran clean on the Slurm side, and a few hours later your scientists started complaining. […]
CryoSPARC v5 crashing daily?
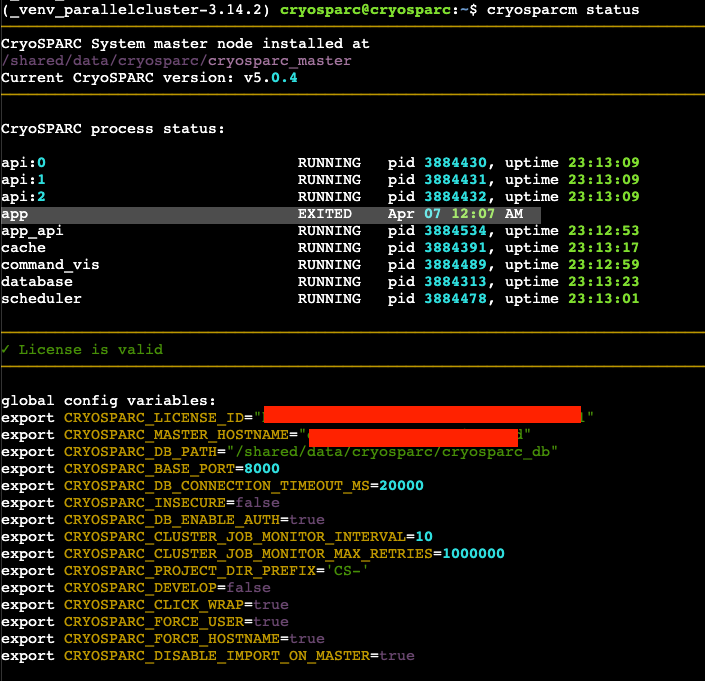
This Post is 100% Google Search Bait This is one of those short-form posts I throw up, hoping that someone in the future using Google does not waste the time that I did debugging this issue. If you are dealing with an issue where the CryoSPARC v5 application from the fine folks at https://cryosparc.com is […]
PCS or ParallelCluster for Schrödinger Suite?

Everything you never wanted to know about PCS and PCluster for Schrödinger Workloads but have been forced to find out Why? It’s rare for me to simultaneously work on ParallelCluster and PCS for the same workload, and I learned some things, enough to justify writing some words about it. Hope someone finds it useful! Drivers […]
AWS Parallelcluster Monitoring
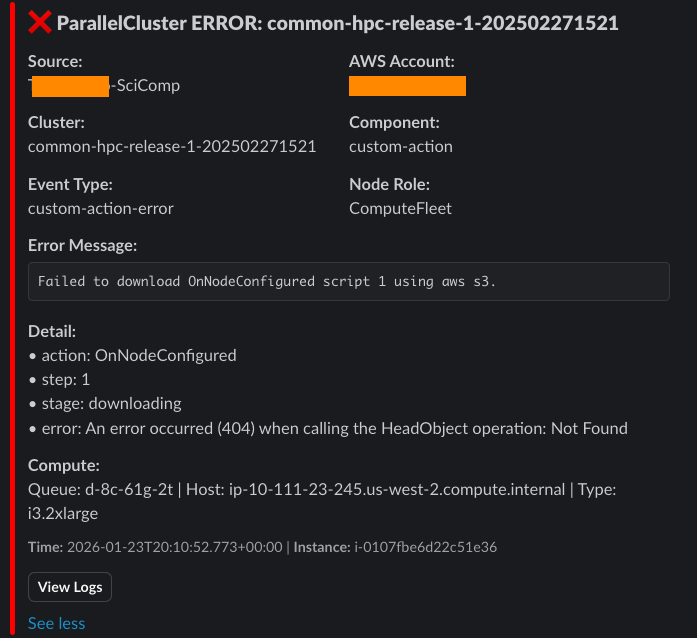
Stop finding out about HPC cluster problems from frustrated users. This post walks through some basic experiments with a Terraform-based approach to proactive AWS ParallelCluster monitoring, using CloudWatch Subscription Filters and Lambda functions to push real-time alerts—including Protected Mode warnings, capacity errors, and bootstrap failures—directly to Slack.
ParallelCluster, External Destinations & Firewall Rules

When Internet egress is blocked by default inside your cloud environment, what external sites and destinations need to be allowed for AWS Parallelcluster?
Integrating Elastic Cloud Kibana with Okta SAML SSO in 2021

Why this post? This post is 100% search engine bait designed to help others avoid the pitfalls I encountered while integrating our hosted ElasticSearch cluster with our Okta SSO environment. The specific issues encountered were that the Elastic Cloud post discussing Okta integration provides slightly incorrect guidance on the setting of a particular elasticsearch.yml parameter. […]
AWS ParallelCluster Private Deployment in Hardened VPCs
Image: Firing up a public cluster configured to deploy through a logging Squid proxy was the only way to discover all of the various Internet-based URls and endpoints that AWS Parallelcluster needs in order to successfully complete a full deployment. AWS ParallelCluster Private Deployment in Hardened VPCs Executive Summary If you are struggling like […]
2016 HPC Trends from the Trenches
Chris has been delivering his “trends from the trenches” presentation at the BioIT World Conference & Expo since 2010 and the talk has evolved into a fairly popular annual tradition. The intent of the talk is to deliver a candid (and occasionally blunt) assessment of the best, the worthwhile, and the most overhyped information technologies (IT) for […]